اهمیت و تفاوت Disallow و allow در فایل robots.txt و تاثیر آن در SEO سایت
فایل robots.txt در ریشه قرار دارد و هدف آن جلوگیری از ورود خزنده های موتورهای جستجو به صفحات خاص است . اما در دستورات این فایل امکان مسدود سازی کل Url ها یا تعداد خاصی از Url قابل تعریف است .
ساختار کلی دستورات به شکل زیر است
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]یک نمونه فایل robots.txt
www.example.com/robots.txtمسدود سازی ورود خزنده ها به همه محتوای سایت حتی صفح اصلی
User-agent: *
Disallow: /دستور زیر اجازه وارد شدن به همه آدرس ها را میدهد حتی صفحه اول . تفاوت این با دستور فوق حذف شدن / از انتهاب Disallow است
User-agent: *
Disallow: برای مسدود سازی یک مسیر خاص یا دایرکتوری دستور زیر استفاده میشود : این دستور فقط به Googlebot این را دستور میدهد که اجازه ورود به این مسیر را نمیدهد
User-agent: Googlebot
Disallow: /example-subfolder/مسدود سازی یک صفحه در bing : دستور زیر به خزنده bing اجازه دسترسی به صفحه زیر را نمیدهد
User-agent: Bingbot
Disallow: /example-subfolder/blocked-page.htmlبرخی نکات دیگر در مورد robots.txt
- نام فایل از نظر موتورهای جستجو به حروف کوچک و بزرگ حساس است و باید فقط با حروف کوچک نوشته شود مانند robots.txt
- فایل robots.txt باید در ریشه یا همان مسیر public در هاست قرار داشته باشد
- دستورات تعریف شده در فایل robots.txt برای برخی از خزنده ها در نظر گرفته نمیشود مانند malware ها به منظور یافتن آدرس های ایمیل در صفحات وب سایت
- دسترسی از طریق url باید برای این فایل باز باشد و با زدن آدرس آن در مرورگر محتویات آن دیده شود www.example.com/robots.txt
- هر ساب دامنه باید فایل robots.txt خود را داشته باشد و ساب دامنه ها از یکدیگر مجزا هستند.
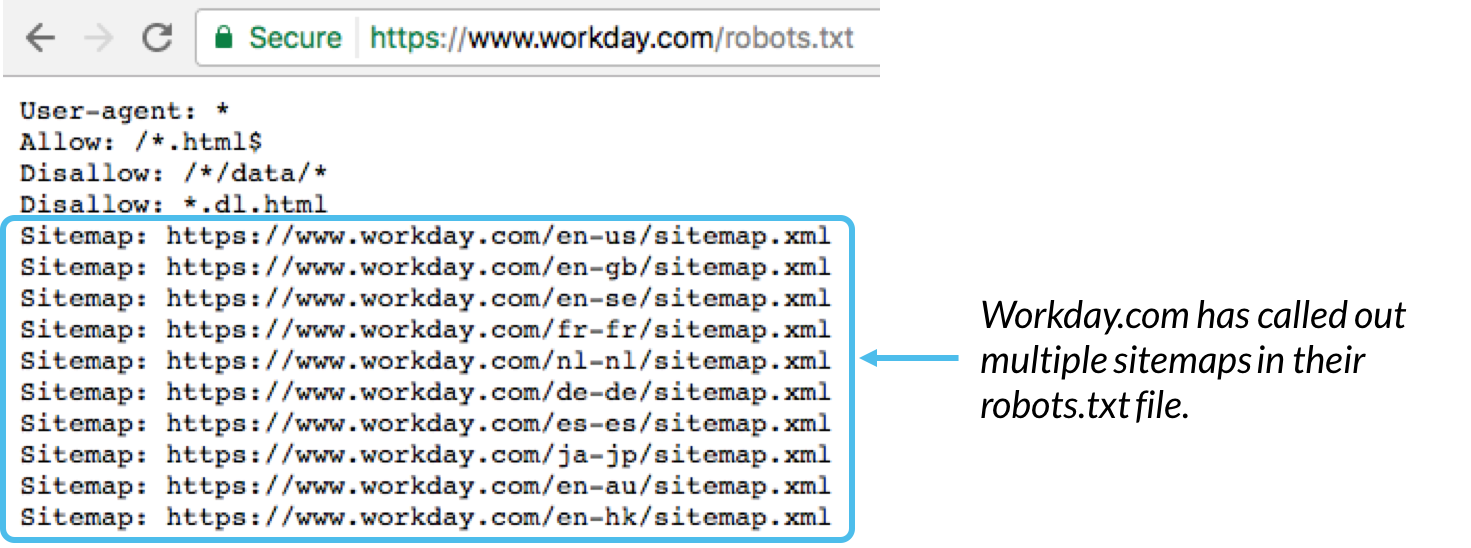
- در تعریف استاندارد sitemap ها می توان آنها را در فایل robots.txt اضافه کرد.
دستورات موجود در این فایل بر اساس زبان استاندارد robots.txt تعریف میشود . به طور کلی 5 دستور برای استفاده درنظر گرفته شده است
- User-agent : این دستور بیانگر نام موتور جستجو خاص است مانند google یا bing در https://www.robotstxt.org/db.html
- Disallow : این دستور به تنهایی اجازه ورود به همه صفحات را میدهد اما اگر در ادامه آن آدرس یا علامت / قرار بگیرد از ورود به کلیه صفحات خوداری میکند
- Allow : این دستور تنها برای Googlebot شناسایی میشود و این اجازه به طور کامل برای ایندکس کردن کلیه صفحات و یا دایرکتوری ها را به خزنده میدهد
- Crawl-delay : این دستور برای گوگل قابل شناسایی نیست اما میگوید که خزنده چند ثانیه میتواند قبل از بارگذاری محتوا در وب سایت باقی بماند . اما با تعریف مقادیر crawel rate در وب مستر تولز گوگل میتوان این موضوع را پیگیری کرد
- Sitemap : اجازه تعریف آدرس های sitemap.xml را میدهد تا موتورهای جستجو بتوانند همه آدرس های sitemap یا نقشه سایت را شناسایی کنند.